GeForce RTX 50: Nvidia udgiver teknisk hvidbog til Blackwell 51-kommentarer

Billede: nvidia
Nvidia har udgivet hvidbogen til Blackwell-arkitekturen bag GeForce RTX 50. Med dette dokument adresserer Nvidia relevante ændringer mellem arkitekturerne og forklarer nye funktioner.
Et dybere blik på arkitektur
Efter GeForce RTX 5080-testene og i sidste uge GeForce RTX 5090-testene blev offentliggjort, kan Blackwell-hvidbogen på Nvidias hjemmeside nu kaldes frem.
Selvom præsentationen af Blackwell-arkitekturen hovedsageligt blev arbejdet med nøgleord, og de viste grafer viste relativt små arkitektoniske ændringer mellem ADA Lovelace og Blackwell, går hvidbogen videre. Størrelsen på hvidbogen på 57 sider viser, at der ligger meget mere bag Blackwell og frem for alt en masse fremtid.
Blackwell med et blik
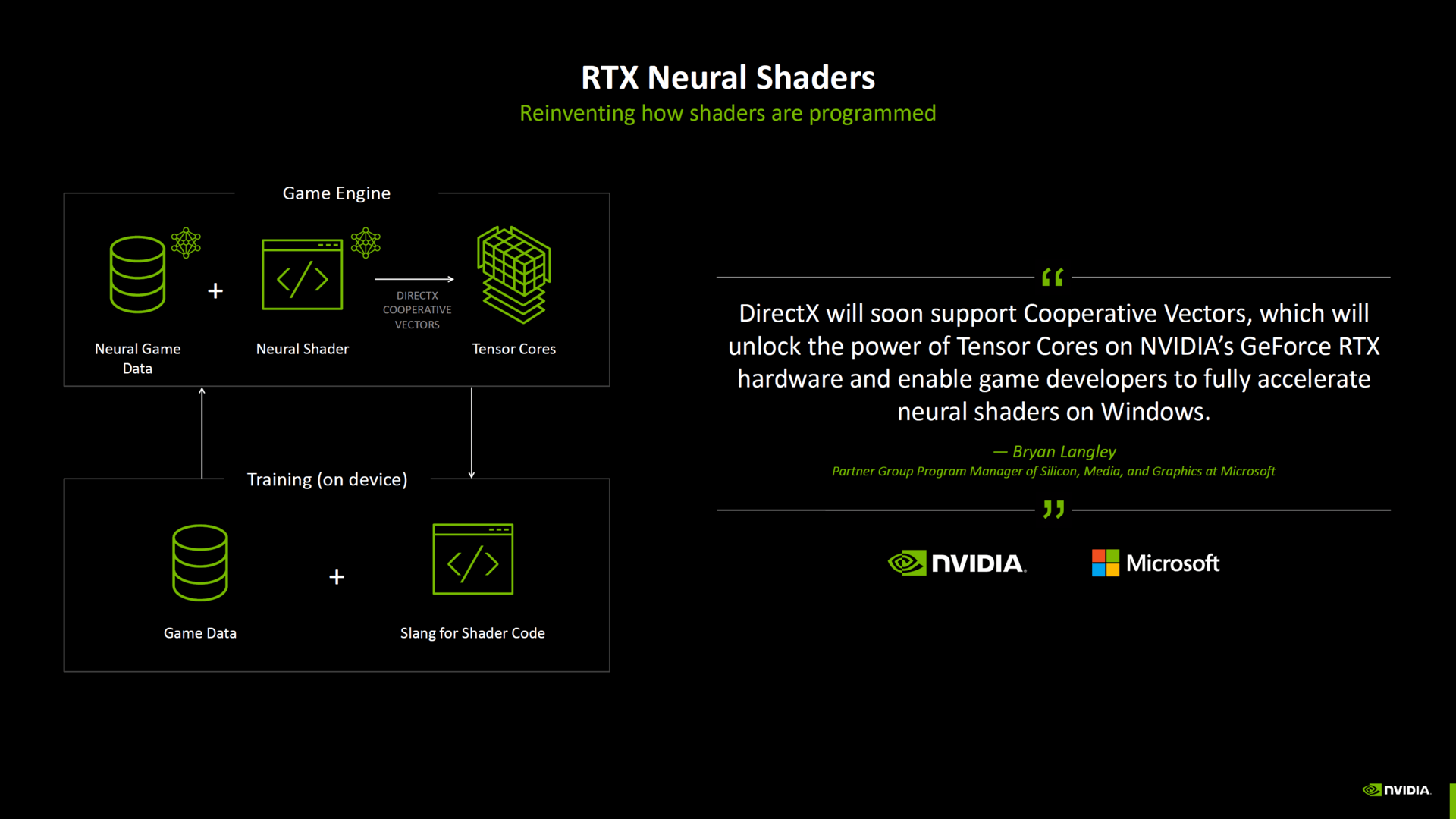
I begyndelsen af hvidbogen skrev Nvidia selv, at Blackwell blev udviklet til den næste generation af AI-medier og -applikationer. Nvidia navngiver følgende punkter:
SM til neural-Q shading-funktioner til forbedring af energieffektiviteten4. Generering af RT-Kerne5. Tensor generation Kernenvidia DLSS 4RTX Neural Shaderai Management Processor (AMP) GDDR7-Steicherga Geometry
Hvidbogen præsenterer disse punkter mere præcist baseret på ændringerne mellem ADA Lovelace og Blackwell og beskriver mulighederne.
For eksempel er ændringen i streaming multiprocessorer mellem Blackwell og Ada Lovelace beskrevet nærmere. I grafikken fra Blackwells præsentation kan vi for SM se, at 32 shaders nu udfører beregningerne eller FP. Hos ADA Lovelace og Ampere var kun 16 shaders i stand til at håndtere 32-bit antallet af ganzers og flydende kombinationsnumre, de andre 16 aluses pr. shader partition var ude af stand til at udføre FP-beregninger.
Med denne ændring mister Blackwell dog en kapacitet i Ada Lovelace, som Nvidia introducerede med Turing: Int- og FP-beregninger kan ikke længere udføres i en bar-cyklus i en shader-partition.
 Blackwell Neural Shader (Billede: Nvidia)
Blackwell Neural Shader (Billede: Nvidia)
Mega geometri og reoler
Nvidia lægger særlig vægt på megageometri i hvidbogen og dens effekter på egerkerner. Med megageometri burde der ikke længere være behov for at bruge lavopløsningsproxyer til strålesporingseffekter. Dette er beregnet til at give moderne LOD (detaljeringsniveau) systemer, såsom nanite i Unreal Engine 5, mulighed for at beregne strålesporingseffekter med fuld detalje.
NVIDIA beskriver to store forhindringer, der forhindrer strålesporingseffekter i at blive beregnet i moderne LOD-systemer med fulde geometridetaljer: “klyngebaserede LOD-opdateringer” og det store antal forskellige objekter i moderne spil. NVIDIA introducerer PTLAS (Partitioned Higher Level Acceleration Structure) og udvider dermed den klassiske TLAS (Higher Level Acceleration Structure).
Mega Geometry-funktionen er tilgængelig for alle RTX-grafikkort siden Turing. Under DirectX 12 kan udviklere bruge NVAPI på funktioner. Der er en producentudvidelse til Vulkan, og Nvidias Optix modtager indbygget support til version 9.0.
Og meget mere
Ud over ændringerne fra Blackwell til Ada Lovelace og den nye megageometri, som kort præsenteres her, er der andre ændringer, som ville gå ud over omfanget på dette tidspunkt. Hvis du vil lære mere om Blackwell og Neural Shader, har du nu de nødvendige dokumenter med hvidbogen.
NVIDIA GEFORCE RTX 5090 I testen: DLSS 4 SCORES MFG 575 Watt i formatnvidia Geforce RTX 5080 i testen: DLSS 4 MFG og en lille FPS-Boostnvidia Geforce “Blackwell”: Tekniske detaljer på RTX 50090 & lackwell “5090, 5090 & 5090, 5090 og 5090 Tekniske detaljer om RTX 5090, 5080 & 5070 (Blackwell”: Tekniske detaljer om RTX 5090, 5080 & 5070 Ti) Nvidia DLSS 4: Multi-frame generation og et nyt neuralt netværk Nvidia Reflex 2 i detaljer: For eksempel reducerer Frame Warp latens i alle nvidia geforce RTX 5000-scenarier – RTX 5080 RTX-specifikationer 5070 Arkitektur Blackwell GPU GB203 GB205 GB205 Transistorer 92,2 milliarder 45,6 milliarder 45,6 milliarder 31,1 milliarder størrelse 750 mm² 378 mm² 263 mm² SM 170 84 70 48 FP32-ALUS 614600 CORES. 170, 4. gen 84, 4. gen 70, 4. gen 48, 4. genkerner 680, 5. gen 336, 5. gen 280, 5. gen 192, 5. gen boost clock 2.407 MHz 2.452 MHz 2.512 TMHz 4 MHz 0,512 Tfps ydeevne 4 MHz Tflops 43,9 Tflops 30,9 Tflops FP16 ydeevne 104,8 Tflops 56,3 Tflops 43,9 Tflops 30,9 Tflops FP16 ydeevne via tensor 419 TFlops 175,8 TFlops 123,5 Teksturenheder 2 ROPS 8 ROPS 8 176 112 96 80 L2 -CACH 98.304 KB 65.536 KB 49.152 KB Hukommelse 32 GB GDDR7 16 GB GDDR7 12 GB GDDR7-THROULHPUT 28 GBP 960 GB/s 896 GB/s 672e slot 5.0 × 16 videomotor 3 × NVEC (9. generation)
2 × NVDEC (6. generation) 2 × NVENC (9. generation)
2 × NVDEC (6. generation) 2 × NVENC (9. generation)
1 × NVDEC (6. generation) 1 × NVENC (9. generation)
1 × NVDDC (6. Genp) TDP 575 WATT 300 Ur 250 Ur: Dangerdi-Dirtiart Raida nvidia nvidia nvidia Sort

Alexandre, uddannet ingeniør, deler sin viden om GPU-ydeevne til gaming og kreativt arbejde.

