GeForce RTX 50: Nvidia publishes technical white paper for Blackwell 51 comments

Image: nvidia
Nvidia has published the white paper for the Blackwell architecture behind GeForce RTX 50. With this document, Nvidia addresses relevant changes between the architectures and explains new features.
A Deeper Look at Architecture
After the GeForce RTX 5080 tests and last week the GeForce RTX 5090 tests were published, the Blackwell white paper on the Nvidia website can now be called up.
Although the presentation of the Blackwell architecture was mainly worked with keywords and the graphs shown showed relatively small architectural changes between ADA Lovelace and Blackwell, the white paper goes further. The size of the white paper of 57 pages shows that there is much more behind Blackwell and above all a lot of future.
Blackwell at a glance
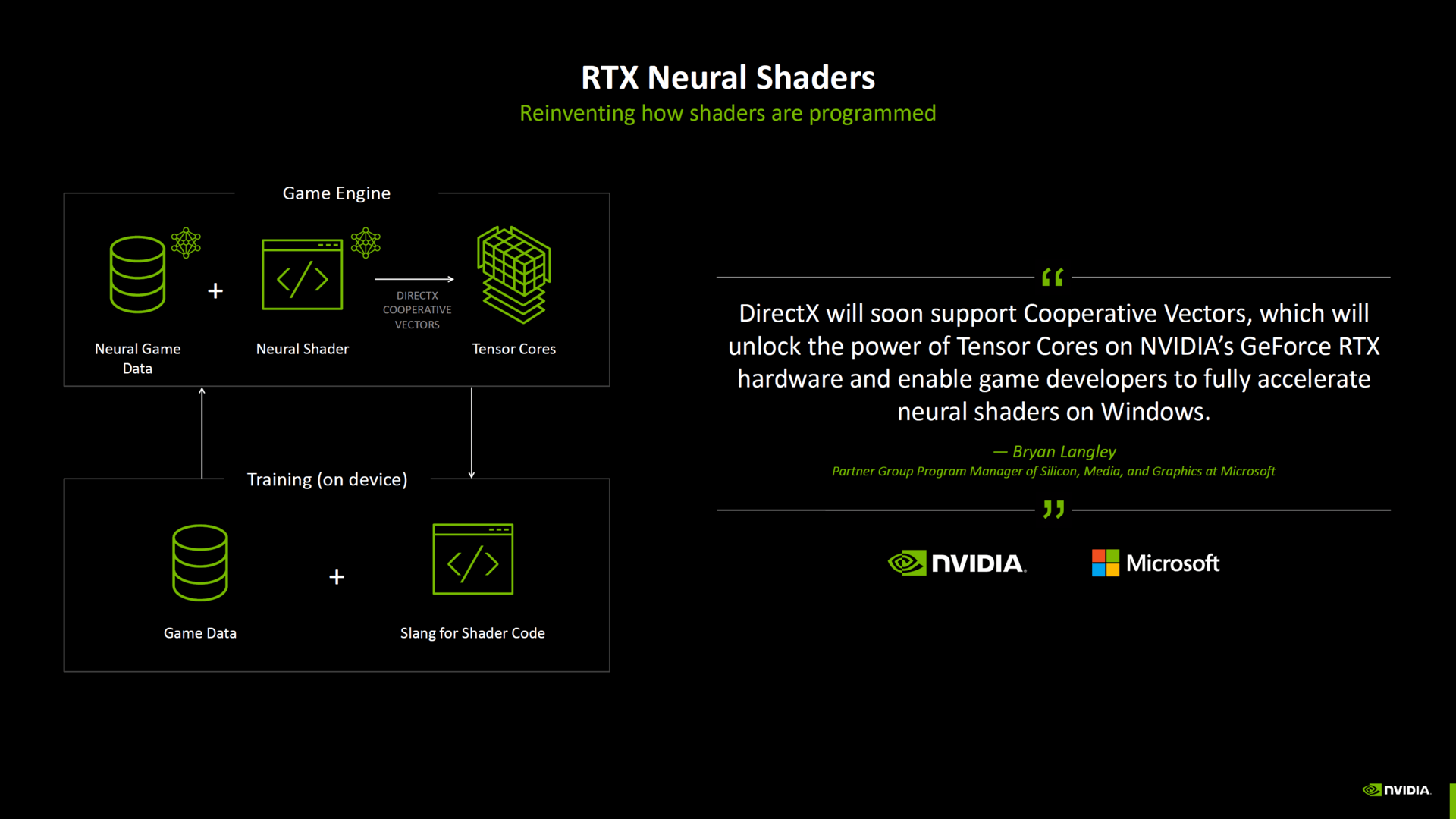
At the beginning of the white paper, Nvidia itself wrote that Blackwell was developed for the next generation of AI media and applications. Nvidia names the following points:
SM for neural-Q shading functions for energy efficiency improvement4. Generation of RT-Kerne5. Tensor generation Kernenvidia DLSS 4RTX Neural Shaderai Management Processor (AMP) GDDR7-Steicherga Geometry
The white paper presents these points more precisely based on the changes between ADA Lovelace and Blackwell and describes the possibilities.
For example, the change in streaming multiprocessors between Blackwell and Ada Lovelace is described more closely. In the graphics from Blackwell’s presentation, we can see for the SM that 32 shaders are now performing the calculations or FP. At ADA Lovelace and Ampere, only 16 shaders were able to handle the 32-bit number of ganzers and liquid combination numbers, the other 16 aluses per shader partition were unable to perform FP calculations.
With this change, however, Blackwell loses a capability in Ada Lovelace, which Nvidia introduced with Turing: Int- and FP calculations can no longer be performed in a bar cycle in a shader partition.
 Blackwell Neural Shader (Bild: Nvidia)
Blackwell Neural Shader (Bild: Nvidia)
Mega geometry and shelving
Nvidia places particular emphasis on mega geometry in the white paper and its effects on spoke cores. With mega geometry, there should no longer be a need to use low resolution proxies for ray tracing effects. This is intended to allow modern LOD (level of detail) systems, such as nanite in Unreal Engine 5, to calculate ray tracing effects at full detail.
NVIDIA describes two big obstacles that prevent ray tracing effects from being calculated in modern LOD systems with full geometry details: “cluster-based LOD updates” and the large number of different objects in modern games. NVIDIA introduces PTLAS (Partitioned Higher Level Acceleration Structure) and thus expands the classic TLAS (Higher Level Acceleration Structure).
The Mega Geometry feature is available for all RTX graphics cards since Turing. Under DirectX 12, developers can use NVAPI on functions. There is a manufacturer extension for Vulkan and Nvidia’s Optix is receiving native support for version 9.0.
And much more
In addition to the changes from Blackwell to Ada Lovelace and the new mega geometry, which are briefly presented here, there are other changes, which would go beyond scope at this point. If you want to learn more about Blackwell and Neural Shader, you now have the necessary documents with the white paper.
NVIDIA GEFORCE RTX 5090 In the test: DLSS 4 SCORES MFG 575 Watts in formatnvidia Geforce RTX 5080 in the test: DLSS 4 MFG and a small FPS-Boostnvidia Geforce “Blackwell”: Technical details on RTX 5090, 5080 & 5070 (Blackwell “: Technical details about RTX 5090, 5080 & 5070 (Blackwell”: Technical details on RTX 5090, 5080 & 5070 Ti) Nvidia DLSS 4: Multi-frame generation and a new neural network Nvidia Reflex 2 in detail: For example, Frame Warp reduces latency in all nvidia geforce RTX 5000 scenarios – RTX 5080 RTX specifications 5070 Architecture Blackwell GPU GB203 GB205 GB205 Transistors 92.2 billion 45.6 billion 45.6 billion 31.1 billion size 750 mm² 378 mm² 263 mm² SM 170 84 70 48 FP32-ALUS 21760 6.960 6.144 RT CORES 170, 4th Gen 84, 4th Gen 70, 4th Gene 48, 4th Gene Kernels 680, 5th Gen 336, 5th gen 280, 5th gene 192, 5th gen boost clock 2.407 MHz 2.452 MHz 2,512 MHz FP32 performance 104.8 Tflops 56 , 3 Tflops 43.9 Tflops 30.9 Tflops FP16 performance 104.8 Tflops 56.3 Tflops 43.9 Tflops 30.9 Tflops FP16 performance via tensor 419 TFlops 175.8 TFlops 123.5 Texture units Tflops 680 336 280 192 ROPS 176 112 96 80 L2 -CACH 98.304 KB 65.536 KB 49.152 KB Memory 32 GB GDDR7 16 GB GDDR7 12 GB GDDR7-THROULHPUT 28 GBP 960 GB/s 896 GB/s 672 GB/s PCIe slot 5.0 × 16 video engine 3 × NVEC (9th generation)
2 × NVDEC (6th generation) 2 × NVENC (9th generation)
2 × NVDEC (6th generation) 2 × NVENC (9th generation)
1 × NVDEC (6th generation) 1 × NVENC (9th generation)
1 × NVDDC (6th Genp) TDP 575 WATT 300 Watch 250 Watch: Dangerdi-Dirtiart Raida nvidia nvidia nvidia Black

An engineer by training, Alexandre shares his knowledge on GPU performance for gaming and creation.

