Samsung e Synopsys: l’accelerazione GPU garantisce velocità alle aziende di semiconduttori 4 commenti

Immagine: nvidia
Il produttore di semiconduttori Samsung Semiconductor e la società di software di progettazione di semiconduttori Synopsys vedono l’accelerazione GPU su NVIDIA HARD e il software Enormi passi avanti nel calcolo delle maschere di esposizione e nella simulazione dei circuiti. Per il GTC 2025 hanno fornito una panoramica delle esperienze precedenti.
Dopo che ASML, TSMC e Synopsys sono stati inizialmente menzionati come sostenitori della libreria software per il calcolo accelerato dalla GPU delle maschere di esposizione per l’annuncio iniziale di Nvidia Culitho, Samsung Semiconductor ora vuole utilizzarla nella produzione.
Culitho accelera la litografia computazionale
Si prevede che Nvidia culitho supporterà e accelererà la litografia computazionale, ovvero i calcoli di correzione ottica di prossimità (OPC) e la tecnologia di litografia inversa (ILT), che finora sono stati eseguiti sui processori e hanno richiesto molto tempo. Come in molti settori, anche in futuro si prevede che anche le GPU effettueranno questi calcoli e i tempi saranno notevolmente ridotti. La litografia computerizzata spiega il resoconto dell’annuncio originale e l’uso seriale su Synopsys e TSMC.
Samsung riduce il tempo di elaborazione a un sesto
In generale, i calcoli OPC potrebbero anche essere accelerati utilizzando le GPU, la libreria software Culitho, una delle oltre 400 nel portafoglio Cuda-X di NVIDIA, può portare ad un’ulteriore accelerazione o garantire inizialmente enormi balzi rispetto al puro calcolo della CPU.
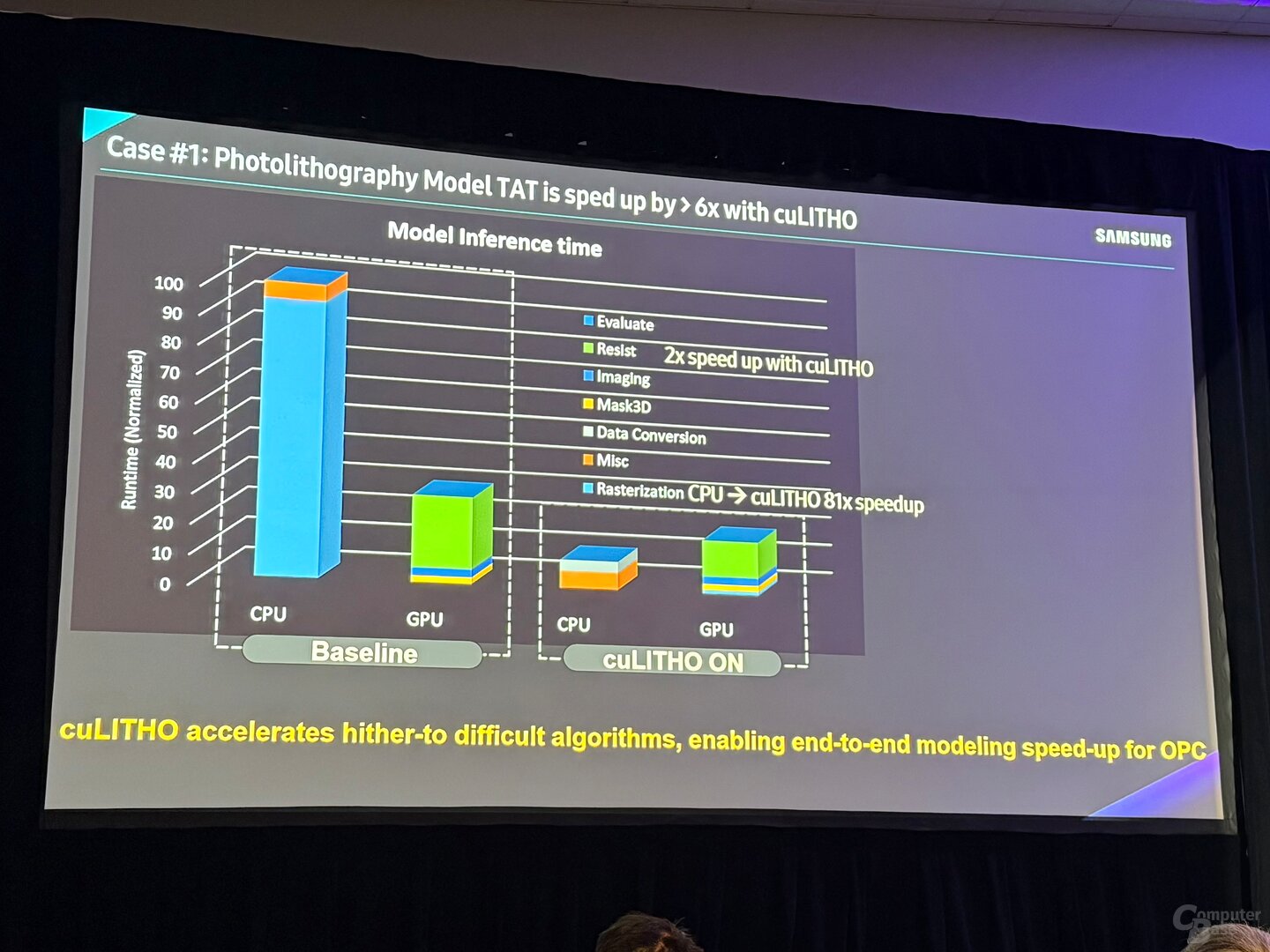
Calcolo della maschera con GPU Samsung Figura 1 di 2
Nella fotolitografia, Samsung Semiconductor è riuscita a ridurre il tempo di calcolo dell’inferenza a un quarto con il supporto delle GPU, poi a un sesto con Culitho. Culitho viene utilizzato anche per nuovi processi di incisione, che sono spesso più vantaggiosi per il business rispetto al processo di litografia, che potrebbe ridurre della metà il lead time (ACT), ovvero il tempo di elaborazione. Secondo l’azienda, il calcolo si basa su un cluster GPU con A100.
15 volte la velocità delle sinossi
L’intelligenza artificiale viene utilizzata anche in diverse aree per la sinossi della società di software di progettazione di semiconduttori (EDA). Ad esempio, l’azienda offre ai propri clienti un copilota (Synopsys.ai Copilot) nel proprio software in grado di rispondere a domande, generare script o creare riepiloghi.
Nvidia Culitho inizialmente ha assicurato OPC e ILT con acceleratori A100 per un calcolo 5 volte più veloce, con la nuova sinossi H100 raggiunge una velocità di 15 volte e per l’aggiornamento a H200 l’azienda prevede un aumento di un fattore 20 volte rispetto al calcolo della CPU.
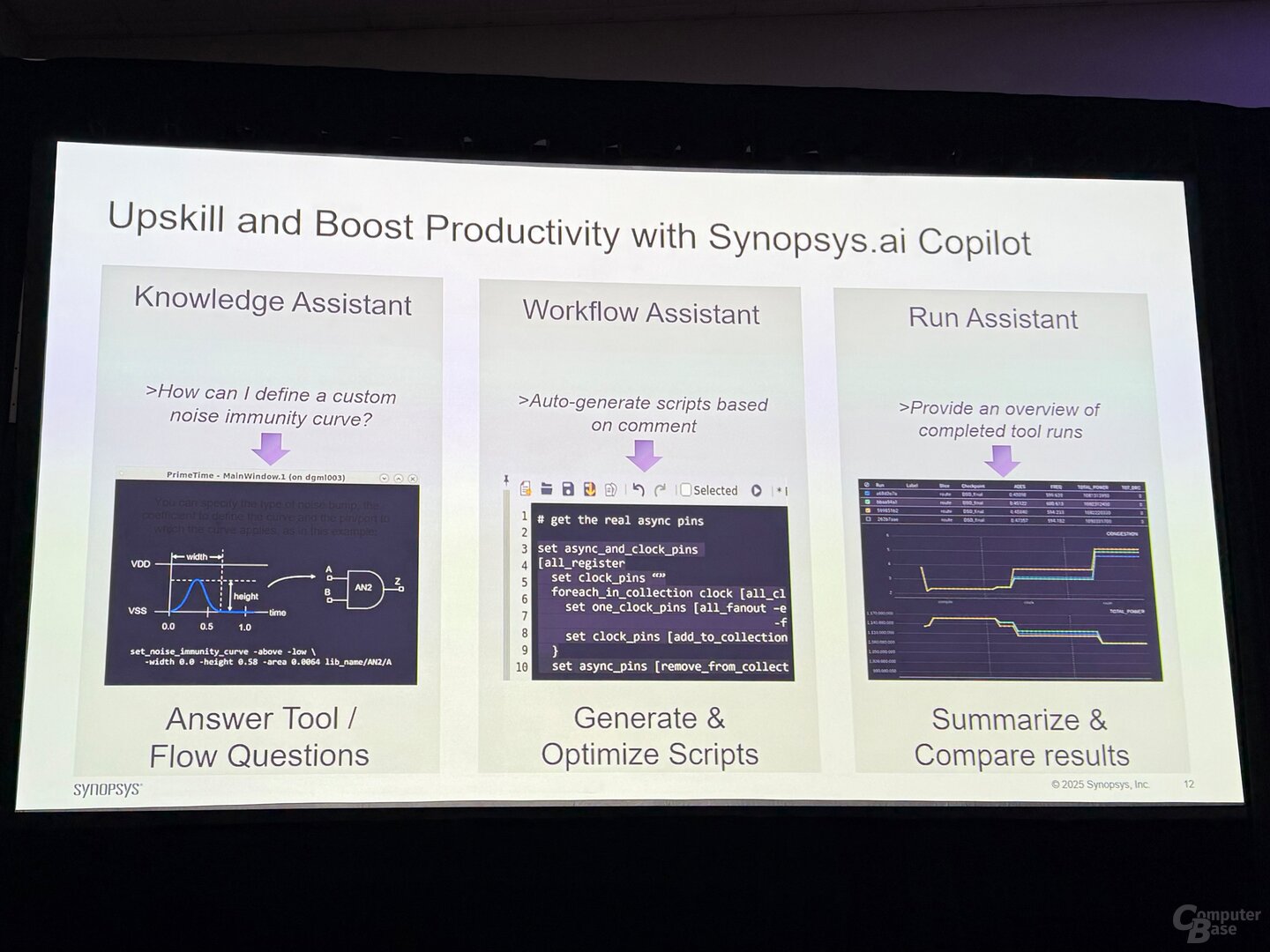
Sinossi Copilota Immagine 1 di 3
La simulazione del circuito richiede giorni
Synopsys si affida inoltre alle GPU NVIDIA per la simulazione dei circuiti e l’analisi dei membri RC all’interno del proprio software Primesim. Per l’analisi dei membri RC della rete di distribuzione dell’energia (PDN), ovvero l’alimentatore che utilizza il silicio via (TSV) utilizzando l’esempio di uno stack HBM multistrato, Synopsys ha più di 70 milioni di membri RC nell’alimentatore e 10 milioni di MOSFET per gli strati HBM effettivi che devono essere esaminati per eventuali errori. Questa attività in Synopsys Primesim quando si utilizzano processori, 14 ore con un GH 200 e solo 6 ore con quattro GH200 richiede 30 ore.
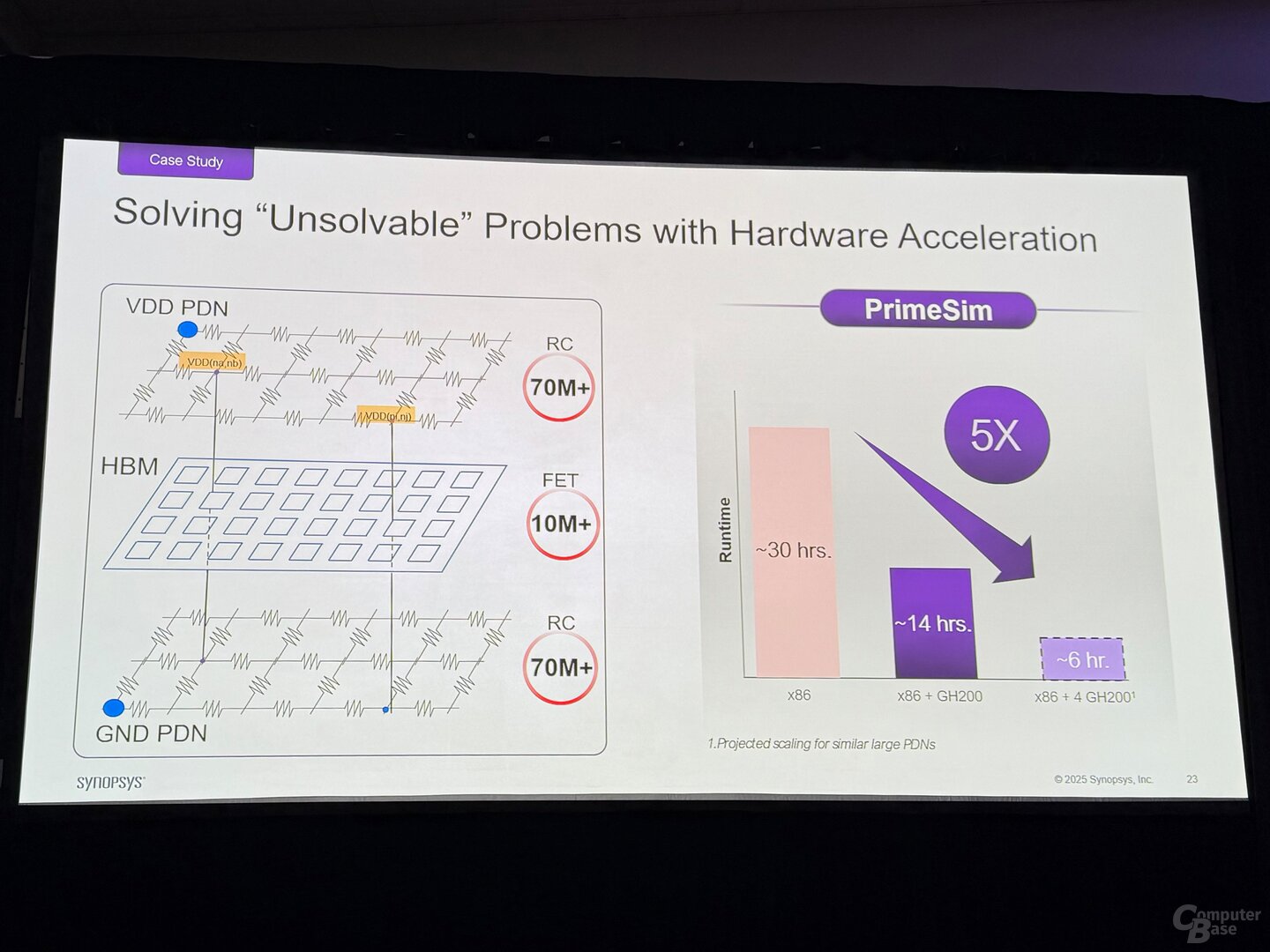
Rete di distribuzione dell’energia alla HBM alla Synopsys Immagine 1 di 4
In Flash ci sono più di 40 milioni di membri RC di alimentatori più 150 milioni di transistor a effetto di campo (FET). Lì, per l’analisi utilizzando il processore ci vogliono 104 ore, 39 ore con Nvidias A100 e 23 ore con quattro acceleratori AMPERE. Per una SRAM, l’analisi della rete di erogazione di potenza con 400 milioni e quindi molti più membri RC occupa la CPU per 19 giorni. Utilizzando la GPU H100, il processo può essere ridotto a 6 giorni o tre H100 a 3 giorni, quasi sette volte più brevi.
Techtip ha ricevuto informazioni su questo articolo da Nvidia come parte di un evento del produttore a San Jose, California. Le spese di arrivo, partenza e cinque sistemazioni alberghiere sono state a carico dell’azienda. Non vi è stata alcuna influenza da parte del produttore né obbligo di segnalazione.
Argomenti: Nvidia Semiconductor Industry Intelligenza artificiale Nvidia GTC 2025 Processori Samsung Fonte: Nvidia, Samsung, Synopsys

Marc decodifica i processori testando le loro prestazioni per gaming, creazione di contenuti e intelligenza artificiale.

